Pandas 판다스
데이터 분석과 처리를 쉽게 할 수 있게 도와주는 파이썬 라이브러리
- 시리즈(Series) : 리스트와 딕셔너리 두 가지의 장점을 섞어놓은 듯한 자료구조
- 데이터 프레임(DataFrame) : Row와 Column으로 이뤄진 2차원 형태의 자료구조. 시리즈(Series)의 결합체
- 넘파이배열 < 시리즈 < 데이터 프레임
- 엑셀과 같은 구조를 가졌다고 생각함
판다스 패키지 필요
import pandas as pd
시리즈(Series)를 활용한 데이터 생성
: 1차원 데이터

Series 데이터를 출력하면 데이터 앞에 index가 함께 표시됨.
s의 인덱스만 표시
s.index
✅ 출력 결과
RangeIndex(start=0, stop=5, step=1)
# 인덱스 범위에 대한 설명
# 시작 ~ 마지막 -1 , 간격
이렇게 결과 내용을 처음엔 뭔 소린가 했음.. 지금쯤이니 그나마(?) 겨우 뭘 이야기하는지 파악함
s.values
✅ 출력결과
array([10, 20, 30, 40, 50])
- 딕셔너리로 이용하여 키(keys)와 값(values)이 데이터의 index와 values
s1 = pd.Series({'국어' : 100,
'영어' : 95,
'수학' : 85,
'한국사' : 90})
s1
✅ 출력결과
국어 100
영어 95
수학 85
한국사 90
dtype: int64
데이터 프레임(DataFrame)을 활용한 데이터 생성
: 행과 열이 있는 2차원 데이터
# 기본 구조?>
df = pd.DataFrame(데이터 [인덱서 = 인덱스값 , 컬럼 = 컬럼데이터])예시)
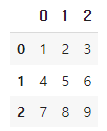
df = pd.DataFrame( [[1, 2, 3] , [4, 5, 6] ,[7, 8, 9]] )
df✅ 출력 결과 : 인덱스와 컬럼값을 입력하지 않았지만 자동으로 생성
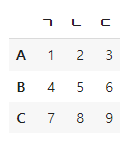
데이터 생성 시 인덱스와 컬럼명 설정 가능함.
인덱스 = ['A','B','C'] , 컬럼명 = ['ㄱ', 'ㄴ', 'ㄷ']으로 설정
pd.DataFrame( [[1, 2, 3] , [4, 5, 6] ,[7, 8, 9]], index = ['A','B','C'], columns = ['ㄱ','ㄴ','ㄷ'] )✅ 출력 결과
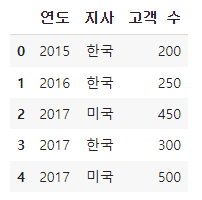
- 딕셔너리를 이용하여 데이터 생성
# 일단 데이터 생성
data_li = {'연도' : ['2015','2016','2017','2017','2017'],
'지사' : ['한국','한국','미국','한국','미국'],
'고객 수' : ['200','250','450','300','500']}
# 데이터 프레임으로 생성
df = pd.DataFrame(data_li)
df✅ 출력 결과
여기까지 ㅡ 이것보다 더 활용 많이 되지만 눈이 너무 아픔... 너무 오래 모니터 들여다본 듯...
728x90
'파이썬(Python) > 데이터 분석' 카테고리의 다른 글
| DataFrame - 수정 (U)_rename (0) | 2022.08.30 |
|---|---|
| DataFrame - 수정(U) (0) | 2022.08.29 |
| DataFrame - 삭제(D) (0) | 2022.08.29 |
| DataFrame - 컬럼의 집계함수 (0) | 2022.08.29 |
| NumPy (0) | 2022.08.08 |



