반응형
그냥 내가 물어본거
이것저것 짜집기 해둠
내가 볼라고 ㅋㅋㅋ

HTML
웹사이트는 HTML 태그로 데이터를 보여주고 우리는 그 중 필요한 부분만 찾아서 크롤링해야 함.
예: 리뷰, 평점, 날짜 등이 어떤 태그에 들어있는지 알아야 BeautifulSoup으로 정확히 뽑을 수 있음
✅ 필요한 정보의 태그 구조 파악
<li>
...
<div class="star_score">
<em>10</em> <!-- 평점 -->
</div>
...
<div class="score_reple">
<p>
<span class="ico_viewer">관람객</span>
<span>정말 재미있어요!</span> <!-- 리뷰 -->
</p>
</div>
</li>
✅ 크롤링할 때 태그/클래스를 기준으로 선택
# 평점은 이 태그
item.select_one('div.star_score > em')
# 리뷰는 이 태그
item.select_one('div.score_reple > p > span')
🔧 실전 팁: BeautifulSoup에서 자주 쓰는 선택자

셀레니움
Selenium은 웹사이트를 자동으로 조작할 수 있는 브라우저 자동화 도구.
우리가 직접 마우스를 클릭하거나 스크롤하지 않아도, Selenium이 웹 브라우저를 켜고, 페이지를 열고, HTML을 가져올 수 있음.
📌 왜 셀레니움이 필요한 이유?
🖥 셀레니움 작동 방식
- 크롬 브라우저를 자동으로 실행
- 사람이 웹사이트 보는 것처럼 페이지를 열고
- JavaScript까지 모두 로드된 HTML을 가져옴
- BeautifulSoup으로 필요한 데이터만 추출
🎯 셀레니움을 배우면 할 수 있는 것
- 네이버 영화 리뷰 크롤링 (JavaScript)
- 인스타그램/트위터 검색어 자동 수집
- 유튜브 댓글 자동 분석
- 쿠팡 상품정보, 블로그 데이터, 쇼핑몰 리뷰 등 크롤링
- 웹 테스트 자동화 (QA에서 활용)
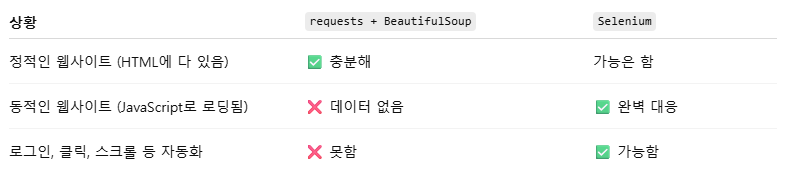
🧾 크롤링 기초 정리: BeautifulSoup vs Selenium
🧩 1. 웹 크롤링 도구 요약

🧰 2. BeautifulSoup을 이용한 기본 흐름
✅ 사용 흐름
import requests
from bs4 import BeautifulSoup
url = "https://example.com"
res = requests.get(url)
soup = BeautifulSoup(res.text, 'html.parser')
# 예시: 제목 가져오기
title = soup.select_one('h1').text✅ 사용 조건
- HTML 안에 데이터가 이미 다 들어있을 때
- 정적 웹페이지일 때
❌ 안 되는 경우
- JavaScript로 불러오는 데이터 (ex. 네이버 영화 리뷰)
- 로그인, 스크롤, 클릭이 필요한 웹페이지
🧭 3. Selenium을 이용한 크롤링 흐름
✅ 사용 흐름
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from bs4 import BeautifulSoup
options = webdriver.ChromeOptions()
options.add_argument('--headless')
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
driver.get("https://example.com")
soup = BeautifulSoup(driver.page_source, 'html.parser')
driver.quit()✅ 사용 조건
- 웹페이지가 동적으로 로딩될 때 (JS 실행 필요)
- 스크롤, 클릭, 로그인 등 사람이 하는 동작이 필요할 때
🧪 4. 예시 비교
📍 정적인 사이트 (BeautifulSoup)
- 뉴스 기사
- 공공 데이터 포털
- 블로그 리스트
📍 동적인 사이트 (Selenium)
- 네이버 영화 리뷰
- 유튜브 댓글
- 인스타그램 피드
- 쇼핑몰 리뷰
🧠 추가로 기억하면 좋은 팁
- select(): 여러 개 태그 선택
- select_one(): 하나만 선택
- headers: 크롤링 차단을 막기 위한 브라우저 흉내
- sleep(): 페이지 로딩 기다릴 때 사용
✅ 지금까지 한 것 요약
- ✔ BeautifulSoup으로 정적 페이지 크롤링 실습 완료
- ❌ 네이버 영화 리뷰는 JS로 로딩돼서 실패
- ✔ Selenium으로 성공적으로 크롤링 + 분석 + 시각화까지 가능함!
728x90
'파이썬(Python) > 크롤링 연습' 카테고리의 다른 글
| 구글 코랩환경에서 셀레니움 이용하기!(25년 05월) (6) | 2025.06.05 |
|---|---|
| 크롤링_멜론차트 TOP100_셀레니움4 (0) | 2023.10.10 |
| 크롤링 - 로또 번호 (0) | 2023.05.25 |
| 크롤링 - 주식데이터 (0) | 2023.04.06 |
| 유튜브 - 재생목록 크롤링 (0) | 2022.12.08 |



